PostgreSQL vs MongoDB
By Pierre-Yves on Sunday, May 20 2012, 11:15 - Général - Permalink

A comparative tests of postgresql vs mongodb
English version
As you may know I have spent some time recently working on the hyperkitty program. The idea being to offer a new interface to the archives in mailman 3 (which has never been closer to a release).
Hyperkitty aims at implementing a numbers of the ideas developed by Máirín Duffy in her blog posts. The main one being to try to unify mailing lists and forum (ie: providing a web-interface to mailing lists).
In this quest, I have started to look some time ago to MongoDB. It is a NoSQL database which is becoming quite popular (probably helped with its integration into openshift). The results were satisfying but then a big question came up:
- Do we really want to impose the burden of 2 different database systems to our sysadmin for a mailman archives interface ?
Of course, if we can avoid it, we would prefer to do it.
But MongoDB was performing really nicely with regards to searching the archives. So testing was needed.
Hardware
The machine on which I ran the test has:
- 16G of ram
- 4 cores
- 2x1To in RAID1
All this operated by RHEL 6.2 (Santiago).
The databases
- PostgreSQL version 8.4.9
- MongoDB version 1.8.2
The data
I used the archives from the devel mailing list, since its creation in 2002.
- PostgreSQL loaded 166672 emails
- MongoDB loaded 166642 emails
So there is a difference of 30 emails which I considered to be negligible for the tests.
The data structure
PostgreSQL
PostgreSQL has one table per list and each table as the same (following) structure:
id serial NOT NULL, sender character varying(100) NOT NULL, email character varying(75) NOT NULL, subject text NOT NULL, "content" text NOT NULL, date timestamp without time zone, message_id character varying(150) NOT NULL, stable_url_id character varying(250) NOT NULL, thread_id character varying(150) NOT NULL, "references" text,
Primary key: id
Index: date, message_id, stable_url_id, subject, thread_id
MongoDB
MongoDB being a NoSQL database using dictionary has a much more flexible structure. For the test the same information was stored in a dictionary structure:
- Content
- InReplyTo
- From
- Subject
- ThreadID
- Date
- References
- _id #internal id defined by MongoDB
- MessageID
UPDATE: The fields which are searched are being indexed. So the following indexes are generated:
- Content
- From
- Subject
- ThreadID
- Date
- References
- MessageID
The queries
11 different types of queries were ran:
- get_thread_length: return how many emails are part of a thread
- get_thread_participants: return the list of all the participants in a thread
- get_email: return a given email based on its message_id
- first_email_in_archive_range: for a time range, return the first email (ordered by date)
- get_archives_range: return all the email in a time range
- get_archives_length: return information of years and month since the creation of the list
- get_list_size: return how many emails are archived for this list
- search_subject: performs a search on the subject of the emails
- search_content: performs a search on the content of the emails
- search_content_subject: performs a search on the subject and the content of the emails
- search_sender: performs a search on the sender of the emails (name and email)
Each queries was run 30 times, thus allowing caching to take place.
The four search queries were ran using both case insensitive and case sensitive queries
Few addition for PostgreSQL:
- the search_sender and search_content_subject queries were ran twice in using a union of queries of simply a or statement
Results
Output
The first we want to know is
- Did the queries return the same results ?
The following queries returned the same result:
- get_email
- get_archives_range
- first_email_in_archives_range
- get_thread_length
- get_thread_participants
- get_archives_length
- search_subject
- search_subject_cs
- search_content
- search_content_cs
The other ones returned different results:
- search_content_subject
** Results differs MG: 28762 PG: 34110 PG-OR: 28762
- search_content_subject_cs
** Results differs MG-CS: 24886 PG-CS: 28578 PG-OR-CS: 24886
- search_sender
** Results differs MG: 1883 PG: 3325 PG-OR: 1883
- search_sender_cs
** Results differs MG-CS: 1882 PG-CS: 1883 PG-OR-CS: 1882
- get_list_size
** Results differs MG: 166642 PG: 166672
For this last query, the difference in the result was expected nothing new there.
But what about the four queries returning different results, well as mentioned the PG{,-CS} queries are using a union of two queries to retrieve the information, so basically what we have is some duplicates. We could remove the duplicate in python easily using a set but as that will only impact the performance even more.
When we compare the results returned by MongoDB with the results returned by PostgreSQL using a or statement, they are similar. So we can conclude that the different queries are returning the same information.
Let's look at their performances now.
Performance
Results are presenting as a boxplot.
Legend:
- CS in the title stands for Case Sensitive query (as opposed to case insensitive)
- MG: results for MongoDB
- PG: results for PostgreSQL
- PG-OR: results for PostgreSQL using a or statement in the query (as opposed to a union)
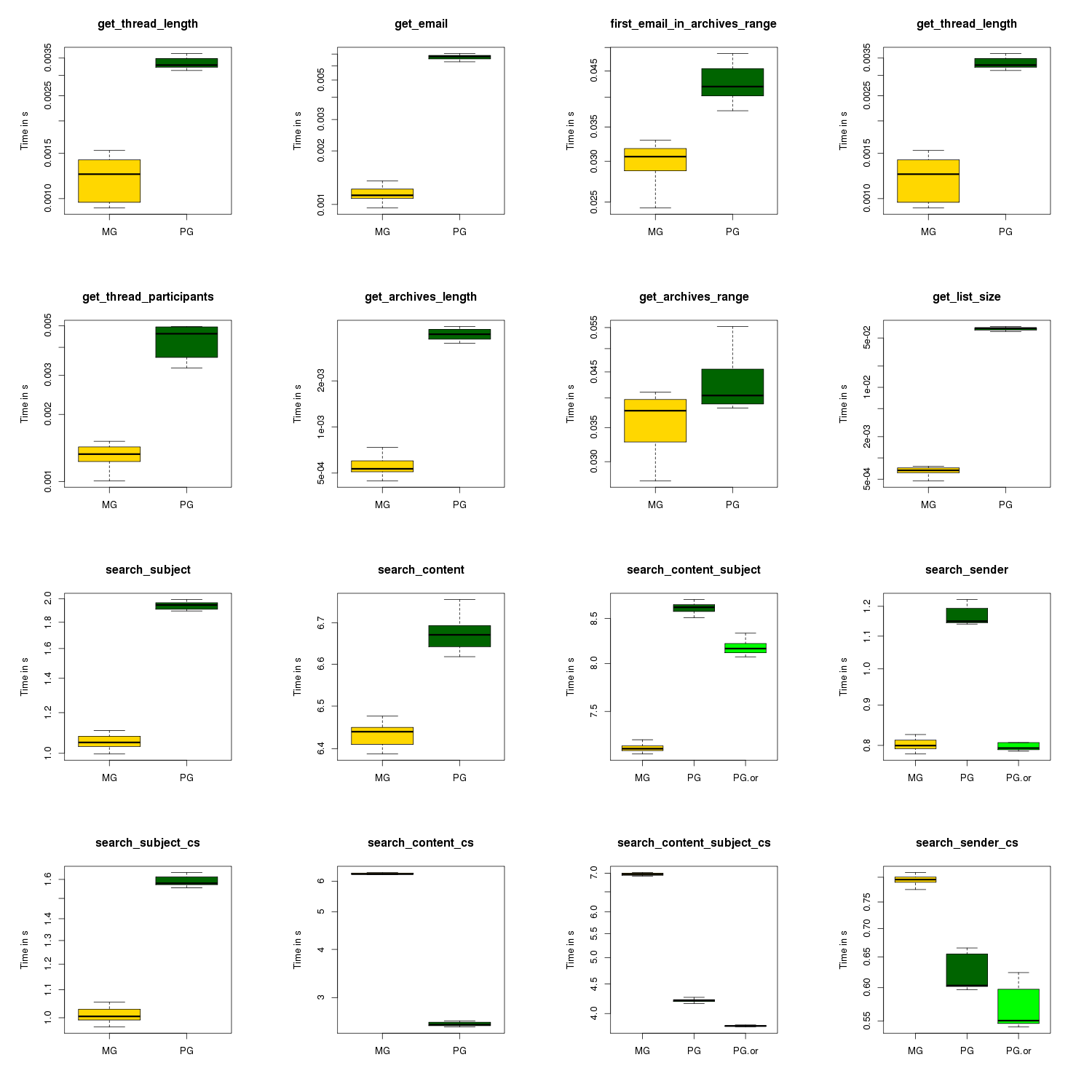
This is a simplified boxplot (as in the outliers are not presented in the picture) but the full boxplot (with the outliers presented) is also available
Additionnal results:
I also looked at the influence of case sensitive vs case insensitive queries within a database system.
MongoDB
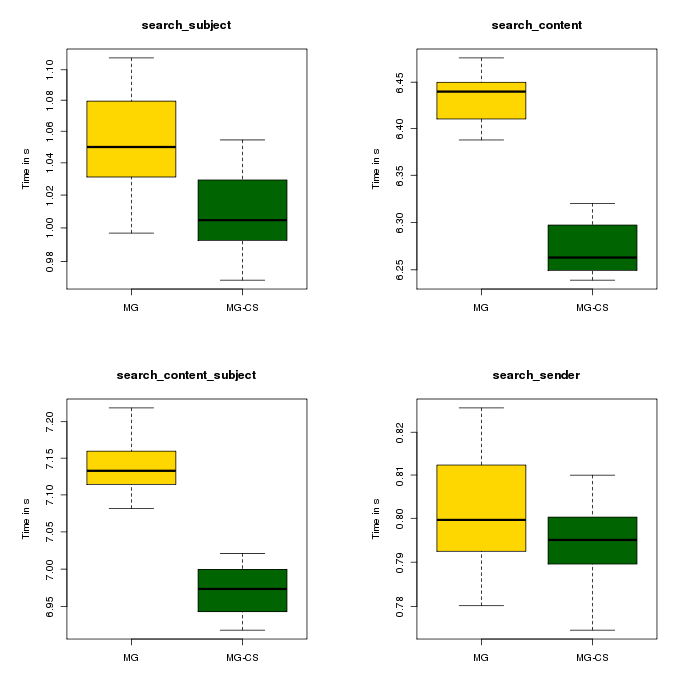
So apparently there is a 'case' effect, but looking at the y scale we can see that this difference is ~0.2 seconds. I believe this is negligible.
PostgreSQL
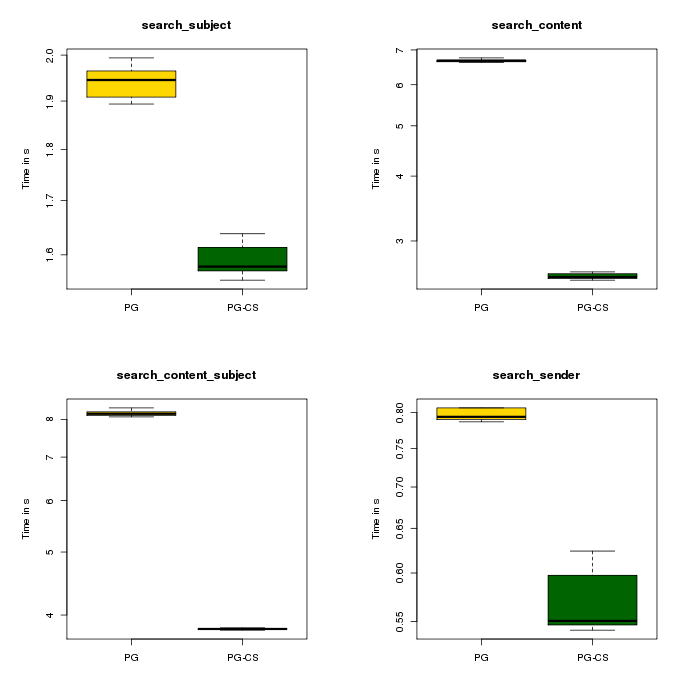
In this case the 'case' effect is much stronger and can go up to ~4 seconds which is much more significant for us.
Conclusions
Looking at the box plot
- PostgreSQL performs worse than MongoDB in the retrieval queries but the time it takes is negligible (we are way under 1 second)
- For PostgreSQL case sensitive queries perform better than MongoDB but worse for case-insensitive queries.
- Case sensitivity in the queries has a greater influence in the performances of PostgreSQL than of MongoDB.
- Or statement should be preferred to union of queries (nothing really surprising there).
So, do we want to perform case-insensitive queries and have 2 database systems to maintain or do we want an option to turn on case-insensitive and have one database system ? Or do we consider 7-8 seconds to be fine while searching in the content of 166000 emails ?
On a final note, everything I used to make the tests and the output of the said tests is available on my git and mirrored on my github.
Comments
About case insensitive search and PostgreSQL, you should build a case insensitive index to get better performances. There is such an example in CREATE INDEX documentation of PostgreSQL.
Thanks for the info, I will look at this (and more precisely, see if SQLAlchemy supports this).
Thanks for the report as it is something I was very interested into. It's good to point out that the conclusions should not be taken looking only at the single query perfomance but there is also an important feature in mongo which should be considered when deciding, its scaling capabilities. At the same time there is a downside, it forces you to have some db logic in the web app, which will also move probably some load over the web server, when compared to postgresql. It would be great to move this analysis further.
@Giulivo,
I am not sure to follow you wrt "it forces you to have some db logic in the web app", could you expand a little bit?
For example, for me, at the moment, I have split my db engine logic outside of the web-app[1], so that actually I can use either postgresql or mongodb without changing the web-app code.
1: https://github.com/pypingou/kittyst... this is the project which implement the interface between the web-app and the db engine.
you might want to test another time with postgres 9.1 or even 9.2 in development atm. it should perform even better. be sure to add appropiate indexes in that case as well.
Hi there, thanks for publishing my comment and add your thoughts.
I might not be mastering mongo but while in some occasions I managed to produce useful queries in javascript [1], in some other occasions I had to add some code on the app [2] because I couldn't make mongo do those operations for me
1. https://github.com/giulivo/opinoid/...
2. https://github.com/giulivo/opinoid/...
I don't know if there are better solutions, but even if there are not, the switch could still be worthwhile if taking the specific "scalability on commodity hardware" feature into account.
@tobias,
I agree, I should try to re-run the tests with newer versions of MongoDB, PostgreSQL and SQLAlchemy.
@giulivo,
Your links appear to be broken but from your description I think I see what you mean.
I took a different approach where I used MongoDB just like another database system (like I would do with PostgreSQL or MySQL), so I have no ajax or so calling the db from the html.
I'd also be curious if you tuned your postgres server to use more RAM than its ridiculously conservative defaults. See http://wiki.postgresql.org/wiki/Tun... for some ideas.
Also from a quick read I did not see any mention of indexes on the mongo DB. If you are doing content specific searches, ie on the subject you should index the subject. Obviously you want to index the most important queries. In this case to me creating indexes on subject and content may significantly increase your times in those areas, but then again it could have zero effect :).
@charlie,
I did not change anything to the configuration of my PostgreSQL, so I use the defaults provided by RHEL.
@ pjwarner,
Good point I forgot the mention it, there are index also in the MongoDB (I will update the post):
- Date
- Email
- Subject
- From
- Content
- ThreadID
- MessageID
- References
That's basically all the fields which are searched and the index are created if needed just before the search.
To give you an idea, you can see the queries there: https://github.com/pypingou/kittyst...
And before the question is asked, I cannot create an index for the content of the emails in PostgreSQL as some emails are too big/long for its taste. There might be an option to tune this but I did not look.
When I last used mongodb (<1.8) you needed very specialized indexes. E.g. mongodb was not able the combine the single indexes you create in https://github.com/pypingou/kittybe... and use it in the query.
This seemed to not have changed:
http://www.mongodb.org/display/DOCS...
You can use the query explain() to see if it does a table scan, and hint() to force a not perfectly fitting index to be used if the query analyzer doesn't choose it.
The Indexing FAQ has more important info like:
* Performance drops if your indexes don't fit in RAM. If you need many of them it
becomes a problem.
* Compound indexes should use the right options and order if you use them for
sorting
All search_(content|subject)*() benchmarks will do a table scan in mongodb anyway because of the `^.*`
regexpression: http://www.mongodb.org/display/DOCS... like postgres for '%...' queries.
Postgres has full text indexes that tokenize the text. It may save you from 'LIKE '%...' queries which are expensive. If you tokenize 'This is textual data' you can search for 'text%' and do not need to search for '%text%'. You can implemnet tokenizing in mogodb within your application logic (http://www.mongodb.org/display/DOCS...) but I don't think that scales for big amounts of data. If you want to offer advanced full text search you can use solr/elastic search/Whoosh for that, but then you again have a second complex component in your stack, even if they give you, beside full text search, facetting, similarity searches, stemming, result highlighting and a lot more. (side note: I can recommend the sunburnt library to access solr.)
Another thing You might also look at the patterns to do pagination in mongodb and rdbmses. If you might get 27000 mails in a result you don't want to deserialize all of them to show 20, and instead do a count() and fetch only the 20 you'd like to display. In sqlalchemy it's a combination of `offset()` and `limit()`. What makes the benchmark times of 7-8 seconds for search_sender|content are mostly the cost for transfering the data for 20000+ mails, not the search. The webhelpers package has a support class to do pagination with sqlalchemy.
In postgres/sqlalchemy side you can use `desc()` to sort decending.
The `KittySAStore.search_content_subject_or*()` methods should not need a `list(set(mails))` at the end.
Is the data you used available to play with? Or maybe I missed the code in the github repo to generate the data.
Cheers,
..Carsten
@Carsten
Thanks for all the feedback.
- Regarding the 1 index/query it says the exception is $or, chance for me :)
But then, I guess the index on Date is not necessary.
- I agree that the pagination should be done at the DB level, that would save quite some time.
- True for the `list(set(mails))` that's a left over from the time it used union.
- Regarding the use of desc() I tried it but was getting weird results (as in the most recent emails were not at the top)
- To regenerate the data, the information are within the "official" kittystore: https://github.com/pypingou/kittyst... Patch always welcome of course ;-)
At the very least change the shared_buffers parameter in your Postgres config. The default is meant to be universally compatible, not provide performance.
@Derek Arnold,
Apparently my configuration is at:
shared_buffers = 32MB
I have doubled it and restarted, let's see how different the results are :-)
I don't query mongo from the html. Here are the two corrected links pointing to the db util. Javascript is executed inside mongo
1. https://github.com/giulivo/opinoid/...
2. https://github.com/giulivo/opinoid/...
@giulivo,
Ok I see what you mean now, thanks :)
@Derek Arnold,
With 64MB I don't see any changes in the results of the searches, the order remains the same and the difference between MongoDB and PostgreSQL also.
Is the RHEL default config at all different from the Postgres default config?
If so, this seems like an awfully specific comparison: a recent (but not latest) patch version of a 3-year-old release, using the config changes made by one Linux distro.
Usually shared_buffers is about 1/4th of system memory, so many gigabytes, in your case. However, I wonder if you are CPU bound (can you check?) in which case using more specialized data types and indexes would help more. You might also want to post the plan of the queries you are issuing (via EXPLAIN) if you want to be sure they are using the index.
I think your work would be interesting to the pgsql-performance mailing lists, although the version is pretty old.
Another thing to worry about (if you are doing this) is SQL compilation time from SQLAlchemy. I like SQLAlchemy, but my recollection is that it is really quite slow at query formation; a cost of its generality.
@Alex,
I do not know precisely. The test might be specific but it is basically using the packages on which we would like to see the application running.
Everything is there to duplicate the work on another platform, let me know if you need help to do so ;-)
@fdr
I can make the shared_buffers 4G but iiuc the documentation mentions some kernel parameters to twick, not sure I want to do this. Plus is it realistic to dedicate 4G of RAM to PostgreSQL for a mailman server? I am not convinced.
If I re-run the tests on a Fedora machine, I'll post the new results allowing us to have a better view on the performance of the newer versions.
Good point regarding SQLAlchemy but I would prefer to keep having an ORM and I started with the one I know best.
I know this a specific test, but some things to consider:
The test dataset is negligible for such a powerful machine.
Test ran with a recent MongDB and an outdated Postgres.
MongoDB uses all available memory, Postgress need to be manually tunned in the config files.
@ Arthur,
- The dataset is negligible for such a machine that's true but I did not tune the database systems to adjust it to the machine.
- For the version I agree and it has been mentioned before but they are the version present in the repos thus the version run on the servers (unless specific work/configuration).
I will try to replicate this test on a Fedora 17 with "only" 8Go of ram to see how it goes then.
Looking over this, I find many critical flaws in this post.
1. Can you post your configuration files? Looking at this I don't see anything to indicate you have configured PostgreSQL in a way where it can actually perform?
2. Your also aware how the MVC model differs from MongoDB's model and your results may be worth very little?
3. I would suggest that your results are flawed due to 1) and that you should update to 9.1 and have a better configured server. (e.g. allocating at least 70% or more memory to effective cache)
@damm,
I believe your questions have already been answered in the previous comments.
And I never said it would be the most fair test possible, I wanted to test two systems for my need using my hardware so I did and these are the results.
@pingou
with regard to the kernel parameters: you definitely want to tune those. All they do is allow more SysV shared memory to be allocated. Oracle has a similar SysV-backed system, and nearly identical settings required. I think there is a high likelihood that these kernel tweaks can and will be made optional in the 9.3 (which is the next-next release). The gory details are that POSIX shared memory lacks a safety feature that SysV shared memory has and mmap is not portable to all systems, if you are wondering as to why the difficulty.
However, as I said, these shared buffer settings may not matter because your data set is very tiny. They probably would boost it by some percentage because it avoids copying out of the kernel buffers and there is some reduced lock contention, but you don't have very many processors and it's not clear to me how many postgres clients you are running with.
I'd like to express a lot of thanks for doing the work to make this benchmark possible, including the code so it can be iterated upon.
you are comparing "2 technologies". Try comparing Postgresql nosql hstore vs Mongodb. Should be interesting.
If you are considering MongoDB then you probably don't care about ACID compliance. Then turn off fsync in PostgreSQL config and test again, you'll be surprised.
Also SQLA does not support expression indexes, you need to create one "manually" via DDL, but attach that to table post-create event in your app and it remains defined by your SQLA layer.
@V,
Thanks for the advise, I just tested it but the difference between MonoDB and PostgreSQL remains about the same.
Right, because youre tests are read only... eh, silly me. ;)
I've experimented with the data using a postres fulltext index to do the search_content() query.
You can find the changes on github: https://github.com/csenger/kittyben... (the sensitive visualizations are broken in the fork).
It takes ~ 0.08 seconds to get the count for 'rawhid*' (~17000 rows). 1 Second to get the plain data with engine.execute() (without using the orm) and ~1.5 seconds to get full objects. The index on 'content' is 165 MB big. As said it can only do postfix wildcard searches. Fetching 30 emails from somewhere the middle of the sorted result set also takes ~ 0.08 seconds.
Beside the pure speed improvement it will also scale much better than table scans cause it needs to load less data into memory.
There is one pitfalls in doing the search_(content|subject)* with *big* result sets in postgres. Postgres might use an index but needs to store the result set in memory to process it further. Otherwise it stores information in which parts of the table results where found, and scans these parts later for hits. The setting to specify the max. amount of memory is `work_mem` and defaults to 1MB. For the full text index searches the result need's to fit into `work_mem` or it will suffer badly. I
http://archives.postgresql.org/pgsq... is a good explanation of the consequences of `work_mem`.
@ Carsten,
Thanks a lot for all this work, I am looking forward to run it here but that already looks pretty awesome :)
Your conclusion that the performance delta is negligible is totally wrong. Clearly on a single transaction basis it might appear that way but when you throw tens of thousands of transactions at the database(s) it will turn into something quite significant. Also, you are really comparing a CAP implementation against an ACID implementation. They solve different problems and therefore you have apples and oranges.
@Richard,
That's kinda of the idea, I have a basket I want to put fruits in it and I wonder which is/are the most appropriate.